Il più recente sondaggio elettorale (SWG per conto di Agorà - RAI3) vede "FARE di Oscar Giannino" al 2,5%. Siamo vicini o lontani dal fatidico 4% necessario per entrare alla Camera dei Deputati? Il sondaggio ha usato un campione di 1500 intervistati, che implica un margine di errore di ±2.5% (che aumenta a ±3.1% se il campione è di 1000 intervistati, e ±4.4% con 500 intervistati). I sondaggi riportano (quasi sempre) queste cifre accompagnandole da altre frasi come "livello di rappresentatività del campione del 95%". Se nel sondaggio 2.5% dei rispondenti si sono espressi per FARE, con un margine di errore di più o meno 2.5% viene naturale concludere che "abbiamo il 95% di probabilità di ricevere fra lo zero ed il 5% dei voti" (aggiungo: se il voto si svolgesse ora).
L'affermazioni non è del tutto corretta, perché (1) l'interpretazione finale è imprecisa o vaga nella migliore delle ipotesi; (2) l'interpretazione corretta assume che il campione selezionato sia casuale e rappresentativo della popolazione degli elettori; (3) assume inoltre che vi siano due forze in campo con rappresentatività uguale. Se uno dei partiti è piccolo, i margini di errore sono diversi.
1. L'interpretazione del margine di errore
Si fa spesso una grossa confusione sull'interpretazione del significato degli intervalli di confidenza, o margini di errore che dir si voglia. Quando un partito viene dato al 35% con un intervallo di confidenza al 95% di ±3%, l'interpretazione corretta è che SE il partito avesse davvero il 35% dei consensi nella popolazione, e SE avessimo la possibilità di effettuare molti sondaggi campionando casualmente sempre lo stesso numero di elettori (ma non necessariamente gli stessi), ALLORA questo partito riceverebbe in ciascuno di quei campioni fra il 32% ed il 38% dei voti nel 95% di questi campioni (95% circa, in realtà la percentuale di campioni con questa caratteristica si avvicina al 95% all'aumentare del numero dei campioni effettuati). In altre parole, solo nel 5% dei campioni si otterrebbe un numero di votanti per quel partito inferiore al 32% o superiore al 38%.
Se questo significhi, come spesso si tende a pensare quando si leggono i sondaggi, che quel partito prenderà fra il 32 ed il 38% dei voti con probabilità 95%, dipende da varie cose, non ultima una discussione noiosa e in parte filosofica su cosa pensiate significhi la parola "probabilità" con la quale non voglio tediare me stesso e soprattutto voi lettori.
2. La selezione del campione
Non parlo molto di questo aspetto perché non ne so granché, basti dire che la vera difficoltà per il sondaggista sta nella selezione del campione. Insomma questo è l'aspetto più importante, in un certo senso. Fai il sondaggio via internet? Rischi di sovrastimare i giovani, che hanno preferenze elettorali diverse dagli anziani. Usi l'elenco del telefono? Non trovi i giovani che hanno solo il cellulare... etc... Il sondaggista quindi deve correggere il campione, esercizio difficile ed in parte arbitrario. Questa è la prima causa dell'imprecisione dei sondaggi, ed influisce in modo speciale nel tentativo di rilevare la forza elettorale di partiti minori.
3. L'asimmetria delle forze in campo
I margini di errore riportati, come ho detto, assumono che vi siano due partiti di uguali dimensioni in termini di elettorato. Spesso si dimentica che il margine di errore non dipende solo dalla dimensione del campione, ma anche dall'asimmetria dell'elettorato. Quando i partiti hanno consistenza diversa, il margine di errore, a parità di dimensione del campione, è inferiore (in valore assoluto) a quello riportato, ma può essere molto più grande in percentuale per il partito più piccolo. Inoltre, il margine di errore quando i partiti sono diversi non è simmetrico attorno alla media. Ho fatto dunque alcune simulazioni assumendo una grande popolazione di elettorii, e ho calcolando l'intervallo di confidenza. I risultati sono riportati nella seguente tabella:
| Dimensione campionaria | Consistenza del partito | Intervallo di confidenza 95% |
|---|---|---|
| 500 | 2.5% | 1.2% - 3.8% |
| 1000 | 1.6% - 3.5% | |
| 1500 | 1.7% - 3.3% | |
| 500 | 4% | 2.4% - 5.8% |
| 1000 | 2.8% - 5.3% | |
| 1500 | 3.1% - 5% | |
| 500 | 6.5% | 4.4% - 8.8% |
| 1000 | 5% - 8.1% | |
| 1500 | 5.3% - 7.8% |
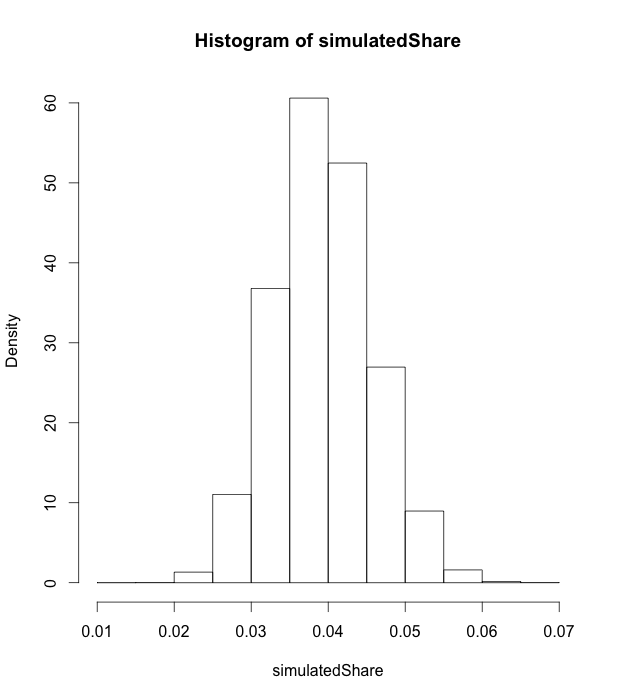
La figura riporta in dettaglio i risultati dei votanti al partito con forza del 4% su 5000 campioni di 1000 persone (su una popolazione di 5 milioni di elettori - quest'ultimo parametro ha solo un piccolissimo effetto sui risultati per dimensioni così grandi della popolazione). Come si può vedere, alcune simulazioni producono risultati vicini al 2% e superiori al 6% ma la stragrande maggioranza sta fra il 3 ed il 5%, coerentemente con quanto riportato nella tabella sopra.
Appendice
Per chi volesse calcolarsi gli intervalli di confidenza, la formula che fornisce un risultato simmetrico ma approssimato (per i nerds: approssimato perché assume l'approssimazione della binomiale a una normale) dell'intervallo di confidenza è la seguente:
/(n+4))")
dove p è la forza effettiva del partito nella popolazione (per esempio, 0.04 per indicare il 4%), ed n è la dimensione del campione. Aggiungere e sottrarre il valore calcolato dalla formula a p per trovare l'intervallo di confidenza.
Per chi volesse invece simulare i risultati, il codice R è il seguente
# dimensione campionaria
Ncampione <- 1000
# Frazione di votanti per il partito
fidshare <- 0.04
Nelettori <- 5000000
Nsimulazioni <- 5000
# 5 milioni è un numero sufficientemente alto per ottenere una approssimazione ottima.
# Lo stesso vale per il numero di simulazioni: 5000 sono sufficienti
simulatedShare <- c(rep(FALSE,Nsimulazioni))
popolazione <- c(rep(0,Nelettori))
popolazione[1:Nelettori*fidshare] = 1
for(i in 1:Nsimulazioni) {
campione = sample(popolazione,Ncampione, replace=FALSE)
simulatedShare[i] <- sum(campione)/Ncampione
}
simulatedShare<-sort(simulatedShare)
intervallo = c(simulatedShare[round(0.025*Nsimulazioni)],simulatedShare[round(0.975*Nsimulazioni)])
intervallo
hist(simulatedShare)
Sulla dimensione sono incuriosito dai sondaggi di Scenari Politci: dicono di avere un database di 14mila indirizzi mail oltre a raggiungere altri 6mila contatti occasionali con banner etc.
Ovviamente essendo l'utente a prendere l'iniziativa soffrono del problema di autoselezione (chi ha più fanboys risulterà pesare più del dovuto); però i risultati sulle principali coalizioni sembrano in linea con quelli degli altri istituti, e proprio il M5S che a mio avviso più dovrebbe soffrire di sovrastima per l'autoselezone degli utenti viene segnato in netto calo.
Insomma, sembra che 4 anni di attività abbiano aiutato ad omogeneizzare il database dei contatti, oltre il fatto che con 20mila dati riescono potenzialmente a far emergere meglio i partiti altrove sotto-rappresentati.
database di 20mila utenti non significa 20mila risposte. Il tasso di risposta e' molto basso, tutti i sondaggi che vedo contengono al piu' 1500 risposte. Il guadagno in termini di margine di errore e' minimo all'aumentare delle risposte, quindi ci si ferma ad un livello ritenuto "ragionevole"